

 E-Mail Adresse E-Mail Adresse | Vorname/Name |
|---|---|
| bernarda | Andre Bernard |
| bjoern | Björn Voigt |
| buhr | Thomas Buhrmeister |
| tomcat | Torsten Schäfer |
| wert | Jurij Kostasenko |
| Unix-Gruppe: CSLIBZOO |

 Protokoll von 20.4.95
Protokoll von 20.4.95 Kurzreferate: 1) Information Retrieval 2) Klassifikation und Retrievalverfahren 3) Indexierung von Dokumenten, 4) Information Retrieval System
 Ziele
Ziele
 Das Expertensystem Information-Retrieval
Das Expertensystem Information-Retrieval
 Kopplung zwischen WWW und Information-Retrieval
Kopplung zwischen WWW und Information-Retrieval
 Testdaten zum Informations-Retrieval-System
Testdaten zum Informations-Retrieval-System
 Das semantische Information-Retrieval
Das semantische Information-Retrieval
 Format der Testdaten
Format der Testdaten
Uns stehen Daten aus der Datenbank DOMA (Maschinenbau und Fertigungstechnik) zur Verfügung. Die Datenbank liefert bibliographische Hinweise auf deutsche und internationale Fachliteratur des Maschinenbaus und der angrenzenden Fachgebiete. Die Dokumente dieser Datenbank sind sehr gut indexiert und haben eine Vielzahl von Deskriptoren. Die Konvertierung dieser Daten wird als sekundäre Teilaufgabe bearbeitet.
Einen besseren Datenbestand bietet der FTP-Servers für technische Dokumente des Lehrstuhl für Künstliche Intelligenz (IMMD8), FAU Erlangen-Nürnberg. Hier sind sowohl die Dokumente klassifiziert und indexiert, und liegen als Volltext vor. Somit ist es möglich, nicht nur eine Information auf das gesuchte Dokument im Retrievalsystem zu erhalten, sondern auch denn direkten Zugriff auf den Text des Dokuments.
Damit ist folgendes System denkbar und implementierbar:
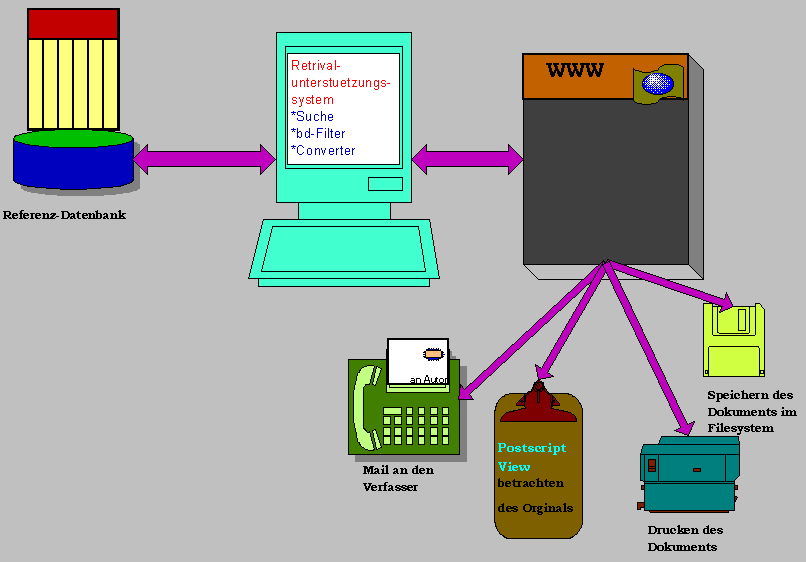
|
|---|
Hier Informationen zum Server

|
Das Dokument kann mit folgenden Deskriptoren erfaßt werden: author title booktitle year editor pages month mail ftp publisher abstract institution number notes school zusammenfassung keywords type number series Klassifiziert werden die Dokumente nach: article memo misc report thesis Weitere Informationen hier.

