Das Expertensystem Information-Retrieval
Ein Information-Retrieval-System hat die Aufgabe Informationen über ein Dokument derart zu speichern, daß mittels dieser Information das Dokument auch eindeutig wiedergefunden wird. Eine solche Abbildung eines Dokumentes muß total sein, d.h. das die Information über das Dokument in seiner Gesamtheit vorliegen muß und sowohl formal als auch inhaltlich das Dokument von anderen Dokumenten differenziert.
Bei einer manuellen Indexierung eines Dokuments kann dieses nicht immer gewährleistet sein. Doch auch die Computergestützte Indexierung kann diese Forderung nicht unbedingt erreichen. Hier spielen die Faktoren des Speicherbedarfs und Zeitbedarfs eine wichtige Rolle.
Eine Abbildung soll die Information eines Dokuments komprimieren, d.h. auf die wesentlichen Inhalte reduzieren und trotzdem das Dokument eindeutig machen, was wiederum mehr Informationen über die gleichenden Dokumente fordert. Ins Extreme ausgeführt, unterscheiden sich die Dokumente erst in ihrer Gesamtheit, was bedeutet, daß die Information über das Dokument das Dokument selbst ist.
Die Identitätsabbildung zu vermeiden, ist die primäre Aufgabe eines Information-Retrieval-Systems.
Dabei werden gewisse Ordnungsregeln formuliert um die Indexierung eindeutig zu machen.
Und gerade hier ist eine Analogie zu den regelbasierten Expertensystemen gegeben.
Regelbasierte Expertensystemen speichern ihr Fachwissen in Fakten und Regeln.
Damit können sowohl Eigenschaften als auch Relationen zwischen den Objekten beschrieben werden und mittels einer WENN-DANN-Inferenz können darüber hinaus Schlußfolgerungen aus den gegebenen Fakten gezogen werden und so daß Fachwissen des Systems erweitert werden.
Die Regeln haben eine einfache syntaktische Form, beschränken sich auf eine Untermenge der natürlichen Sprache (z.B. Attribute, Variablen, Objekte, Aktionen, Beziehungen) und enthalten eine wohlstrukturierte Information der beschriebenden Objekte. Die Regeln und Fakten eines regelbasierten Expertensystemen lassen sich damit als Deskriptoren auffassen, welche mittels gewisser Metaregeln auch automatisch aus einem Dokument gewonnen werden könnten.
Ein mittels einer regelbasierten Methode erschlossenes Dokument läßt die Verwendung einer komplexen anwendungsorientierter Suchstrategie mit Computerunterstützung (CAR: computer aided retrieval) zu und macht die Information über das Dokument dynamisch, d.h. veränderungsfreudlich.
Die Sprache als Abbildung
(Die Metafuktionen)
Wenn man die natürliche Sprache als Abbildung für die Erfassung von Dokumenten einsetzt, so ist es von Interesse, welche Regeln vom Menschen eingesetzt werden um eine relevante Information aus einem Dokument zu extrahieren.
Die natürliche Sprache beinhaltet eine Inhaltsebene und eine Ausdrucksebene.
Die Ausdrucksebene beinhaltet die formalen Symbole mit ihren physikalischen Signalen.
Die Inhaltsebene beinhaltet Codierung und Zuordnung der realen Objekte und ihrer Beziehungen.
Bei einem Dokument kann man diesbezüglich von Bedeutungen und Texten Sprechen.
Die Bedeutung ist der Inhalt des Textes und der Text seine Repräsentation.
Zwischen Texten und Bedeutung bestehen gewisse Entsprechungen:
Jeder Bedeutung kann mehr oder weniger eine bestimmte Menge von Texten entsprechen.
Jedem Text kann mehr oder weniger einer bestimmte Menge von Bedeutungen entsprechen.
Die Regeln, die festlegen, welche Texte welche Bedeutungen bzw. welche Bedeutung welche Texte entsprechen, bilden die Sprachkultur jedes einzelnen Menschen bzw. einer Gesellschaft. Eine Verallgemeinerung ist nicht ohne weiters möglich, so daß die Notwendigkeit der dynamischen Wissensbasis hierbei deutlich wird, was den Einsatz einer flexiblen dynamischen leicht modifizierbaren anwenderfreundlichen Software, eines Expertensystems, fordert.
Damit ist jedoch nicht gesagt, daß es nicht allgemeine Regeln gibt, diese müssen jedoch noch erschlossen werden.
Analogie zwischen Regeln und Deskriptoren
- Sie haben eine feste und eindeutig auflösbare Syntax, d.h. syntaktische Mehrdeutigkeit tritt nicht auf
- Sie verwenden einen beschränkten, kontrollierten Wortschatz und eine bestimmte Anzahl eindeutiger Beziehungen (Relationen) zwischen ihren Elementen (u.a. die Synonymkontrolle und Homonymieauflösunge werden gewährleistet -d.h. semantische Mehrdeutigkeiten treten nicht auf.
Diese Merkmale erlauben eine automatische Erschließung der Regelbestände (d.h. automatische Indexierung, automatische hierarchische Klassifikation von Regeln, Regelteilen und Regeltermen).
Beispiel eines Regelsystems :
säuger(Tier):-
behaart(Tier),
gibt_Milch(Tier).
vogel(Tier):-
fliegt(Tier),
legt_Eier(Tier).
Mit derartigen Regeln, kann sowohl eine inhaltliche Erschließung, als auch eine Klassifikation durchgeführt werden.
Der Suchvorgang kann in zwei Stufen ablaufen
- Grobsuche: Die Regeln werden nur anhand ihrer äußeren Merkmale ausgewählt.
Die Merkmale können z.B. direkt als Thesaurus verwaltet werden. Werden mehrere Regeln aktiviert,
können diese z.B. nach der Anzahl der vorhandenen relevanten Merkmale sortiert werden um den relevanteren Regeln Vorrang zu geben.
- Feinsuche: Die aktivierten Regeln werden nacheinander ausgewählt. Die Auswahl kann durch die Modifikation der Gewichtung beeinflußt werden.
Direkte Abbildung:
Der inhaltliche Dekriptor ist die Bedeutung eines Textes oder eines Anschnitts oder Satzes.
Der Verbindungsdeskriptor (Gewichtungsfaktor) entspricht der Gewichtung der Regeln.
Der Fuktionsdeskriptor kann sowohl als Fakt bzw. auch als Regel eines regelbasierten Expertensystems verstanden werden. Hier können sowohl Relationen zwischen inhaltlichen Deskriptoren bzw. formalen Deskriptoren und Funktionsdeskriptoren als auch Relationen zwischen Funktionsdeskriptoren und Funktionsdeskriptoren, aufgestellt werden. Es können allgemeine Regeln formuliert werden, welche neue Relationen (Fakten) automatisch generieren.
Beispiele für Funktionsdeskriptoren
Eigenschaften von Objekten
'Ausgangsstoff'(Objekt).
'Produkt'(Objekt).
'Verfahren(Objekt).
'Ursache'(Objekt).
'Diagnose'(Objekt).
'Therapie'(Objekt).
Relationen zwischen Objekten
behandelt(Objekt1,Objekt2).
beinhaltet(Objekt1,Objekt2).
benutzt(Objekt1,Objekt2).
beschränkt(Objekt1,Objekt2).
besitzt(Objekt1,Objekt2).
besteht(Objekt1,Objekt2).
bezieht(Objekt1,Objekt2).
dient(Objekt1,Objekt2).
ist(Objekt1,Objekt2).
produziert(Objekt1,Objekt2).
umfaßt(Objekt1,Objekt2).
verursacht(Objekt1,Objekt2).
Regeln
'Firmenprodukt'(Objekt1):-
'Produkt'(Objekt1),
produziert(Objekt2,Objekt1),
Firma(Objekt2).
'Käufer'(Objekt0):-
'Firma'(Objekt2),
produziert(Objekt2,Objekt1),
bezieht(Objekt0,Objekt1).
Bildhaft gesehen wird das Dokument mittels des regelbasierten Expertensystems in ein Netzwerk (Graphen) zerlegt bei dem die Objekte als Knoten und die Kanten als Beziehungen bzw. als Eigenschaften betrachtet werden.
Das Dokument wird durch alte und neu hinzukommenden Deskriptoren in das Gesamtsystem eingebunden, so daß sich dadurch ein Hypergraph ausbildet.
Jedes Dokument bildet mit seinen Deskriptoren eine eigene Klasse und kann eine Oberklasse mit weiteren Dokumenten bilden. Zwischen den Klassen können Hyper-Beziehungen formuliert werden
(z.b. Homonyme, Synonyme, Ober- und Untebegriff, ect.) .
Die folgende Grafik veranschaulicht diese Beziehungen:
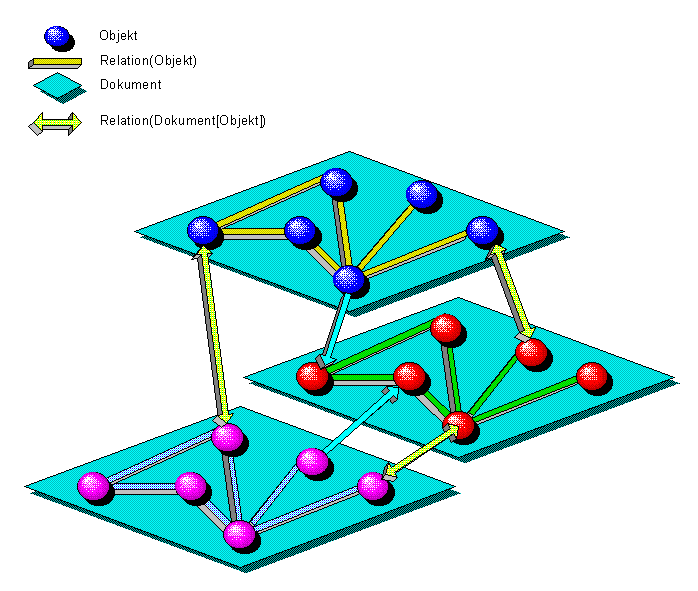
Um die Fakten des Expertensystems auszulagern, bzw. anderen Anwendungsprogrammen bereitzustellen, werden alle Deskriptoren in eine externe Datenbank ausgelagert, und bilden damit den Deskriptorspeicher des Systems.
Das folgende Bild verdeutlicht das hierzu notwendige Datenmodell.
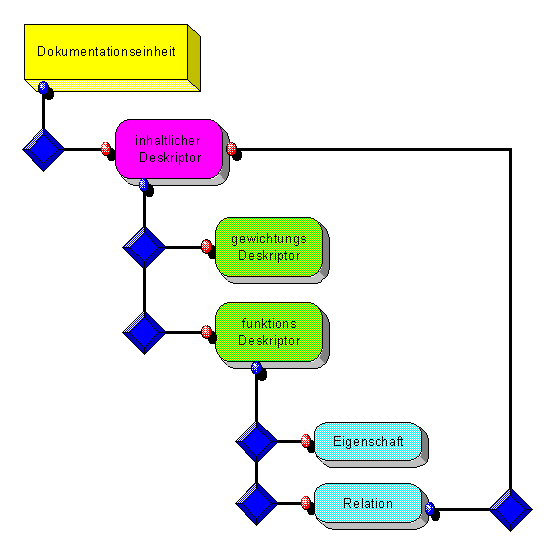
Um einen effizienten und schnellen Zugriff zu ermöglichen wird die hierarchische Struktur des Deskriptorspeichers aufgelöst. Die Tabelle des Deskriptorspeicher kann demnach wie folgt dargestellt werden.
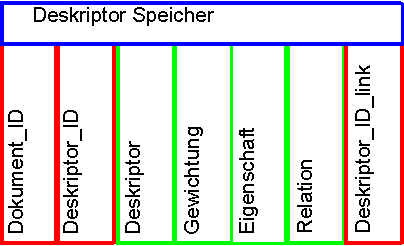
Beispiel für eine Indexierung im Deskriptorspeicher:
Das Dokument
Ein Baum besteht aus Ästen, deren Fortführung die Zweige, die die Blätter tragen, sind.
Indexierung :
- Für den Text relevante Wörter bestimmen:
- Gewichtung (quantitativ) kann z.B. durch Häufigkeit bestimmt werden.
( (qualitative) Gewichtung muß sonst manuell bestimmt werden.)
Deskriptor Gewicht
Baum 1
Äste 1
Zweige 1
Blätter 1
- Bestimmung der Eigenschaft
Deskriptor Eigenschaft
Baum Gewächs
- Bestimmung der Relationen
Deskriptor Relation Deskriptor
Baum besteht aus Äste/n
Äste besitzt Zweige
Zweige besitzt Blätter
Belegung des Deskriptorspeichers
| DokumentID | DeskriptorID | Deskriptor | Gewicht | Eigenschaft | Relation | DeskriptorID_link |
|---|
|
| 1 | 01 | Baum | 1 | Gewächs | besteht | 02 |
| 1 | 02 | Äste | 1 | - | besitzt | 03 |
| 1 | 03 | Zweige | 1 | - | besitzt | 04 |
| 1 | 04 | Blätter | 1 | - | - | - |
|
Werden in der Spalte DeskriptorID_link nicht nur die inhaltlichen Deskriptoren eines Dokuments zugelassen, sondern auch Dokument_ID’s anderer Dokumente, so läßt sich über eine Relation (z.B. Deskriptor[wird definiert in] Dokument ) eine Beziehung zwischen den Dokumenten beschreiben, so daß nicht nur eine hierarchische Beziehung zwischen den
Deskriptoren (Thesaurus) beschrieben werden kann, sondern auch zwischen den jeweiligen Dokumenten.
Damit nun das Information-Retrieval-System eine vollständige Suche auf einer Datenbank durchführen kann, muß im System die Struktur der genutzten Datenbank als externe Wissensbasis gespeichert werden und die Inferenzmechanismen müssen entsprechend angepaßt werden.
Dem System soll ohne Einschränkung möglich sein auf jede beliebige Tabelle einer Datenbank zuzugreifen um die Informationen direkt auslesen zu können. Um den Zeitaufwand bei der Suche der geeigneten Tabellen zu reduzieren, sollen alle Tabellen und deren Einträge als Funktionsdeskriptoren im Deskriptorspeicher gespeichert werden, was zwar einen höheren Speicherbedarf und Redundanz der Daten bedeutet jedoch Retrieval im Zeitverhalten verbessert.
weiters in Planung...
|
Mail an den Verfasser

|