Prinzip der Rückwärtsverkettung
der syntaktischen Struktur beim IndexierenPrinzip der Rückwärtsverkettung
der syntaktischen Struktur beim Indexieren
Prinzip der Rückwärtsverkettung
der syntaktischen Struktur beim IndexierenPrinzip der Rückwärtsverkettung
der syntaktischen Struktur beim IndexierenIn der Ausarbeitung "Das Expertensystem Information-Retrieval" wurde angedeutet, daß die Indexierung die Umkehrung des Retrievals ist. Dieses soll nun an einem Beispiel verdeutlicht werden.
Gegeben sei ein folgendes Dokument:
Originaler Datensatz aus Erlangen:
abstract
Dokument1:
Array =[
[Im Laufe der Zeit wurden eine ganze Reihe verschiedener Formalismen entwickelt, mit deren Hilfe die Semantik natürlicher Sprache beschrieben werden kann]:1. [Einer dieser Formalismen ist die Diskursrepräsentationstheorie (abgekürzt DRT)]:2. [Typisch für die DRT ist die Zweiteilung der zugehörigen Datenstruktur, der Diskursrepräsentationsstruktur (DRS), in ein Universum, daß die von Nominal- und Verbalphrasen eingeführten Diskursreferenten enthält, und in eine Menge von Bedingungen über diesen Referenten]:3. [Traditionell werden die DRSen aus einem Phrasenstrukturbaum top--down konstruiert]:4. [Seit den Arbeiten Richard Montagues wird der $\lambda$--Kalkül verwendet, um die Semantik natürlicher Sprache kompositional zu konstruieren]:5. [Kompositional bedeutet dabei, daß sich die Semantik eines Satzes nur aus der Bedeutung seiner Wörter und seiner syntaktischen Struktur ergibt]:6. [Dieser Ansatz kann auf die DRT übertragen werden, wie Pinkal (\cite{Millies}) und Reyle (\cite{Reyle85}) gezeigt haben]:7. [Durch $\lambda$--Abstraktion können partielle oder prädikative DRSen zu einzelnen Wörtern gebildet werden, aus denen dann mittels $\lambda$--Konversion die Repräsentation des zugehörigen Satzes konstruiert wird]:8. [Die semantische Analyse kann auf verschiedene Art und Weise mit der syntaktischen Analyse eines Satzes verbunden werden: Syntax und Semantik werden entweder parallel oder nacheinander konstruiert]:9. [Werden sie parallel konstruiert, kann dies in einer Datenstruktur geschehen oder es können getrennte Datenstrukturen verwendet werden, die auf unterschiedliche Art und Weise verändert werden]:10.
]
Indexierung:
Im System seinen nun folgende Relationen bekannt.
HT(X,Y) Y ist Handlungsträger von X
Die relevanten Begriffe werden dem Dokument entnommen.
Da die Begriffe direkt aus dem Text entnommen werden, und in Relation gebracht werden, können diese durch Textbereiche, d.h. durch die Angabe eines Intervalls, wenn das Dokument als ein eindimensionales Array aus Zeichen aufgefaßt wird, aus dem Volltext angegeben werden.
Formalismen = [57;68]:Dokument1
Statt "Formalismen" im System neu einzutragen, wird nur die Dokumentidentifikationsnummer gespeichert und der Bereich des Begriffes im Volltext referenziert. Dieses ist zwar eine konsequente Generalisierung der Datenbestände, was noch zusätzlich die Begriffsreferenz des Ursprungstextes ermöglicht, ( d.h. die Quelle des Begriffes ) , jedoch wird dieses im Datenmodell nicht so konsequent verfolgt, da diese Generalisierung teilweise für den Aufbau eines Lexikons bzw. eines Thesaurus hinderlich ist und außerdem das Zeitverhalten des Systems enorm verschlechtern würde. Aus diesen Gründen wird nur auf eine vollständige semantische Struktur verwiesen.
Jeder Satz der Deskriptoren enthält, wird in seiner Bedeutung erschlossen. Hier gibt es grundsätzlich zwei Möglichkeiten des Wertentwicklungurteils in der syntaktischen Struktur Satz, wenn dieser als eine elementare Einheit von Subjekt und Prädikat verstanden wird. Da in dem Beispiel das Dokument ein Abstrakt ist, ist fast jeder Satz "aktiv". Um die Sätze besser Referenzieren zu können, werden die Sätze nummeriert. Das Dokument besteht hierbei aus zehn Sätzen.
Wertbildungsformen:
PS : Prädikatterminus
SP : Subjektterminus
Beispiele für die Verständnis:
Der Satz mit der Nummer 1 kann sowohl bezüglich eines Prädikatterminus als auch bezüglich eines Subjektterminus' beurteilt werden.
PS [1] : Beschreibung der Semantik natürlicher Sprache mit Formalismen.
SP [1] : Semantik natürlicher Sprache beschrieben durch Formalismen.
Wertbildungsformen:
SP [1] : Semantik natürlicher Sprache beschrieben durch Formalismen
SP [2] : Formalismus Diskursrepräsentationstheorie
SP [3] : Zweigeteilte Datenstruktur Diskursrepräsentationsstruktur enthält Referenten Diskursreferenten einer Menge von Bedingungen eingeführt durch Nominal- und Verbalphrasen
SP [4] : Diskursrepräsentationsstruktur konstruiert aus einem Phrasenstrukturbaum
SP [5] : Semantik natürlicher Sprache konstruiert kompositional mit lambda$--Kalkül aus Arbeiten von Richard Montagues
SP [6] : Kompositional ist sich aus der Bedeutung seiner Wörter und seiner syntaktischen Struktur ergebende Semantik.
SP [7] : SP [6] kann auf Diskursrepräsentationstheorie übertragen werden gezeigt durch Pinkal und Reyle
SP [8]: aus partielle Diskursrepräsentationsstruktur zu einzelnen Wörtern gebildet durch $\lambda$--Abstraktion wird
Repräsentation des zugehörigen Satzes konstruiert mittels $\lambda$--Konversion
SP [9]: semantische Analyse verbunden mit der syntaktischen Analyse eines Satzes
Satz Nr. 10 wird nicht für wichtig gehalten
Der Indexierer hat heirbei alle Sätze bezüglich des Subjektterminus' beurteilt.
Aufstellung der Relationen und Benennung der Lexikoneinträge.
Die Lexikoneinträge bilden alle Deskriptoren die nicht im Text erklärt werden.
Lexikoneinträge:
Beispeil für eine Lexikon Definition in Bezug des Themengebietes des Dokuments:
Der Lexikoneintrag "Abstraktion" konnte wie folgt beschrieben werden:
Abstraktion: Die Fähigkeit reale Objekte auf fiktive Objekte abzubilden.
Bildung der Relationen:
SP [1] : BH(Semantik natürlicher Sprache , Formalismen)
beschreiben = BH kann als erweiterte Interpretation der Relation BH aufgenommer werden.
SP [2] : ID(Formalismus ,Diskursrepräsentationstheorie)
SP [3] : BS( ID(Referenten , Diskursreferenten) , BS( ID(zweigeteilte, ID(Datenstruktur, Diskursrepräsentationsstruktur) ), Diskursrepräsentationstheorie )) & BS(ID(Referenten , Diskursreferenten) , EZ( Nominalphrasen , Menge von Bedingungen) & EZ( Verbalphrasen , Menge von Bedingungen ) )
ist typisch für = BS kann als erweiterte Interpretation der Relation BS aufgenommen werden
eingeführt = EZ kann als erweiterte Interpretation der Relation EZ aufgenommen werden
SP [4] : FN( EZ( Phrasenstrukturbaum, Diskursrepräsentationsstruktur ) , topdown)
konstruiert= EZ kann als erweiterte Interpretation der Relation EZ aufgenommen werden
SP [5] : FN( HG( BF(lambda$--Kalkül, Arbeiten von Richard Montagues) , Semantik natürlicher Sprache ) , kompositional) konstruiert= HG kann als erweiterte Interpretation der Relation HG aufgenommen werden
SP [6] : ID( EZ(Wortbedeutung , Semantik )& EZ(syntaktischen Struktur , Semantik) , kompositional) ergebende = EZ kann als erweiterte Interpretation der Relation EZ aufgenommen werden
SP [7] : HT( UM(Diskursrepräsentationstheorie , SP [6]) , Pinkal) & HT( UM(Diskursrepräsentationstheorie , SP [6]) , Reyle)) übertragen = UM kann als erweiterte Interpretation der Relation UM aufgenommen werden gezeigt durch = HT kann als erweiterte Interpretation der Relation HT aufgenommen werden
SP [8]: EZ( VU(HG(Wörter , FN(Diskursrepräsentationsstruktur , partielle)), $\lambda$--Abstraktion), HG($\lambda$--Konversion , Satzrepräsentation))
gebildet durch = VU kann als erweiterte Interpretation der Relation VU aufgenommen werden
gebildet = HG kann als erweiterte Interpretation der Relation HG aufgenommen werden
konstruiert = EZ kann als erweiterte Interpretation der Relation EZ aufgenommen werden
SP [9]: BF(BT(semantische Analyse , syntaktischen Analyse), Satzes) verbunden = BT kann als erweiterte Interpretation der Relation BT aufgenommen werden "gültig" = BF kann als erweiterte Interpretation der Relation BF aufgenommen werden
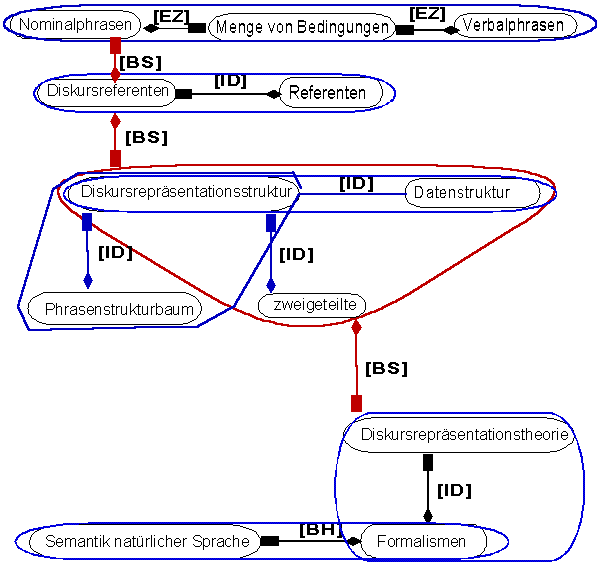
Anmerkungen: Es zeigt sich schon an diesem Beispiel die Notwendigkeit der "interpretierbaren Relation" und die Möglichkeit zur Erweiterung der kontrollierten Relationen im System. Die Relationen zwischen den Betriffen und Sätzen können mittels eines semantischen Netzes veranschaulicht werden. Da schon bei diesem kleinen Beispiel das gesamte semantische Netz unübersichtlich wird, soll nur eine Teilstruktur des Dokuments zur Anschaung gezeichnet werde. Im folgenden Bild werden nur die ersten drei Sätze in einem sematischen Netz dargestellt.